实验四:主元分析
主元分析函数
熟悉函数
1 | from sklearn.decomposition import PCA |
输入参数:
| 参数 | 意义 |
|---|---|
| n_components | 整数表示保留的维度数,小数表示可解释方差占比最小值 |
返回值:
PCA是一个类,该函数是其构造函数,因此返回的是一个对象,要使用主元分析还需要调用该类中的方法fit()
修改参数
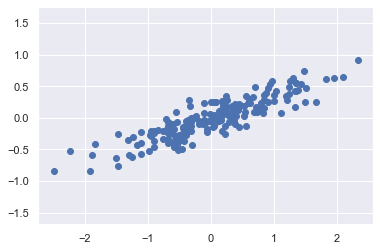
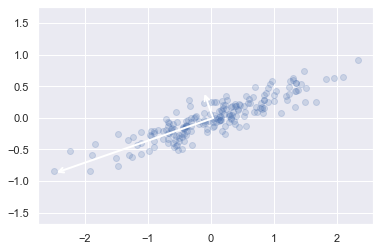
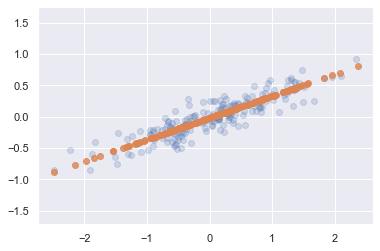
手写数字的 PCA 噪声去除
代码分析
1 | from sklearn.datasets import load_digits |



实验结果
在不同条件下,需要的主元个数:
| 需要的解释方差百分比 | |||
|---|---|---|---|
| 噪声 std | 0.5 | 0.7 | 0.9 |
| 2 | 6 | 13 | 35 |
| 4 | 12 | 26 | 49 |
| 8 | 22 | 37 | 54 |
- 噪声越大,需要的主元个数越多
- 需要的解释方差百分比越大,需要的主元个数越多
人脸 PCA 重建
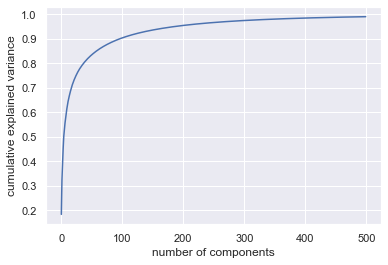
| n_pcs | 累计解释方差比 |
|---|---|
| 50 | 0.833 |
| 150 | 0.936 |
| 300 | 0.975 |
从图中可以看出,降到 100 维左右即可保留至少 90%的信息。
不同维度下人脸重建的效果:




人脸图像 PCA 前后识别率差别
| 主元数 | 识别率 |
|---|---|
| 未降维 | 0.39 |
| 30 | 0.50 |
| 50 | 0.50 |
| 100 | 0.41 |
| 150 | 0.29 |
使用如下代码生成
1 | X = np.linspace(1, 150, 150, dtype = int) |
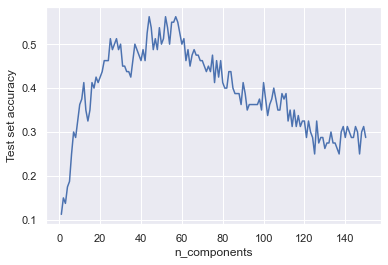
由该图像可以看出,主元数在 50 左右时,人脸重建后的识别率最高