实验二:模型评估与选择(1)
熟悉训练集-测试集划分、流水线和交叉验证函数的使用
训练集-测试集划分函数
1 | from sklearn.model_selection import train_test_split |
输入参数:
| 参数 | 意义 |
|---|---|
| test_size | 0~1 的小数:测试集占原始样本比例;整数:测试集样本数 |
| stratify | 保持划分前的分布(各类样本的占比保持不变) |
| random_state | 随机数种子 |
返回值:
| 返回值 | 意义 |
|---|---|
| X_train | 划分出的训练集数据 |
| X_test | 划分出的测试集数据 |
| y_train | 划分出的训练集标签 |
| y_test | 划分出的测试集标签 |
流水线函数
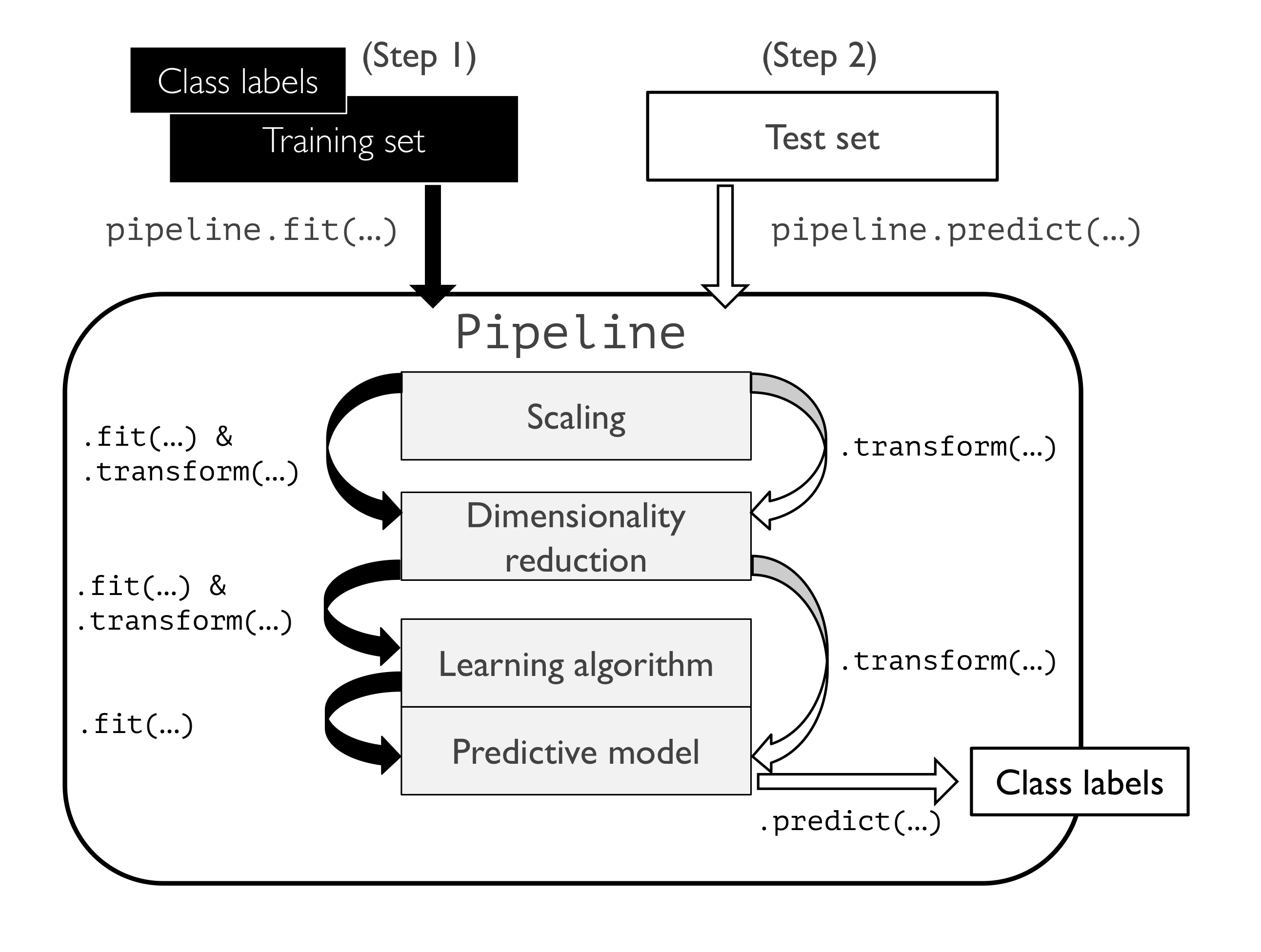
1 | from sklearn.pipeline import make_pipeline |
输入参数:
| 参数 | 意义 |
|---|---|
| *steps | 需要串联的估计器(estimators) |
| **kwargs | 一些关键词参数(memory,verbose) |
返回值:
| 返回值 | 意义 |
|---|---|
| p | 返回一个 Pipeline 对象 |
如示例程序中:
1 | from sklearn.preprocessing import StandardScaler |
pipe_lr 为 Pipeline 类的一个实例,其步骤为:
- 标准化处理(StandardScaler)
- 主成分分析、特征降维(PCA)
- 逻辑回归(LogisticRegression)
交叉验证函数
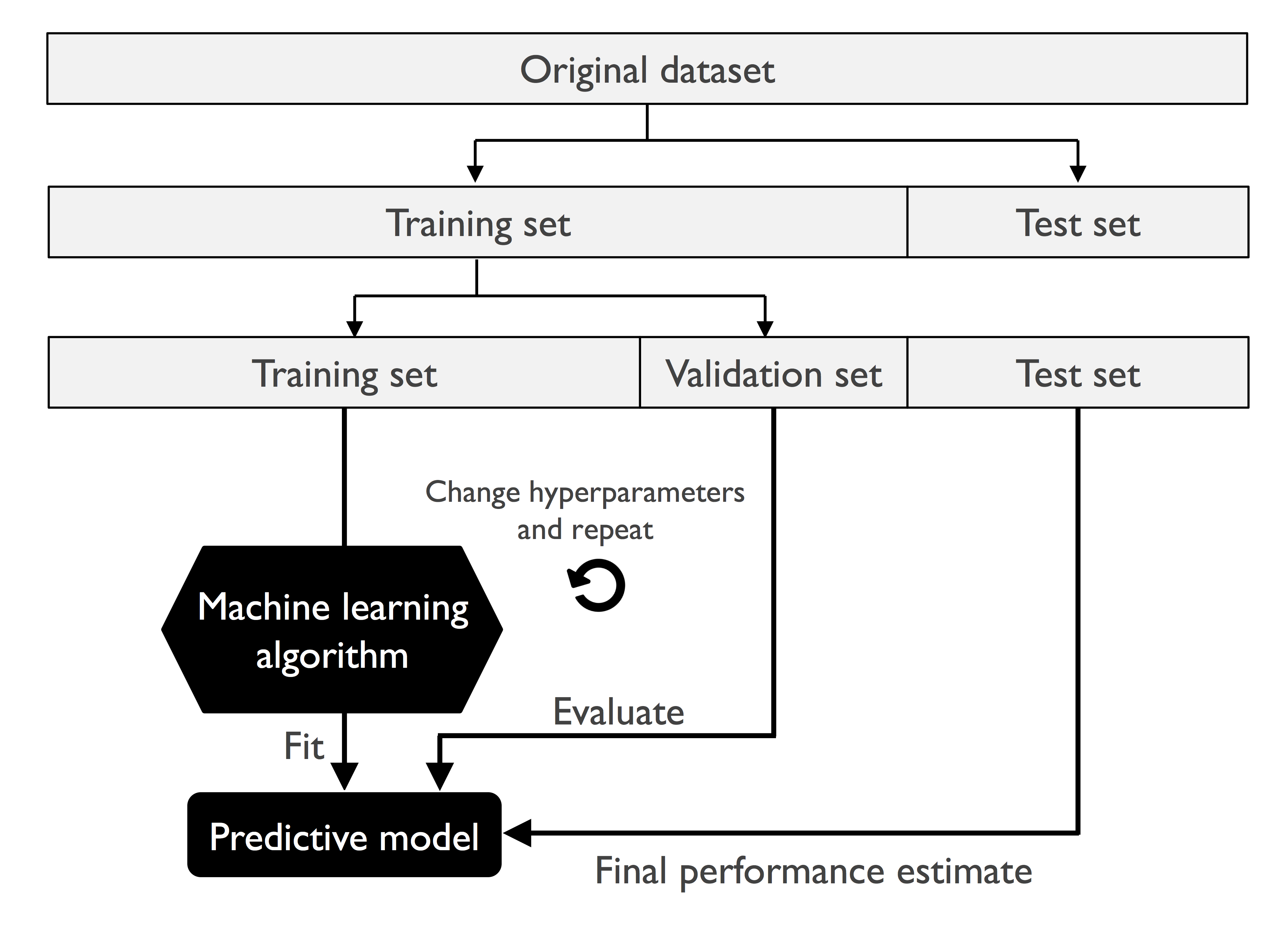
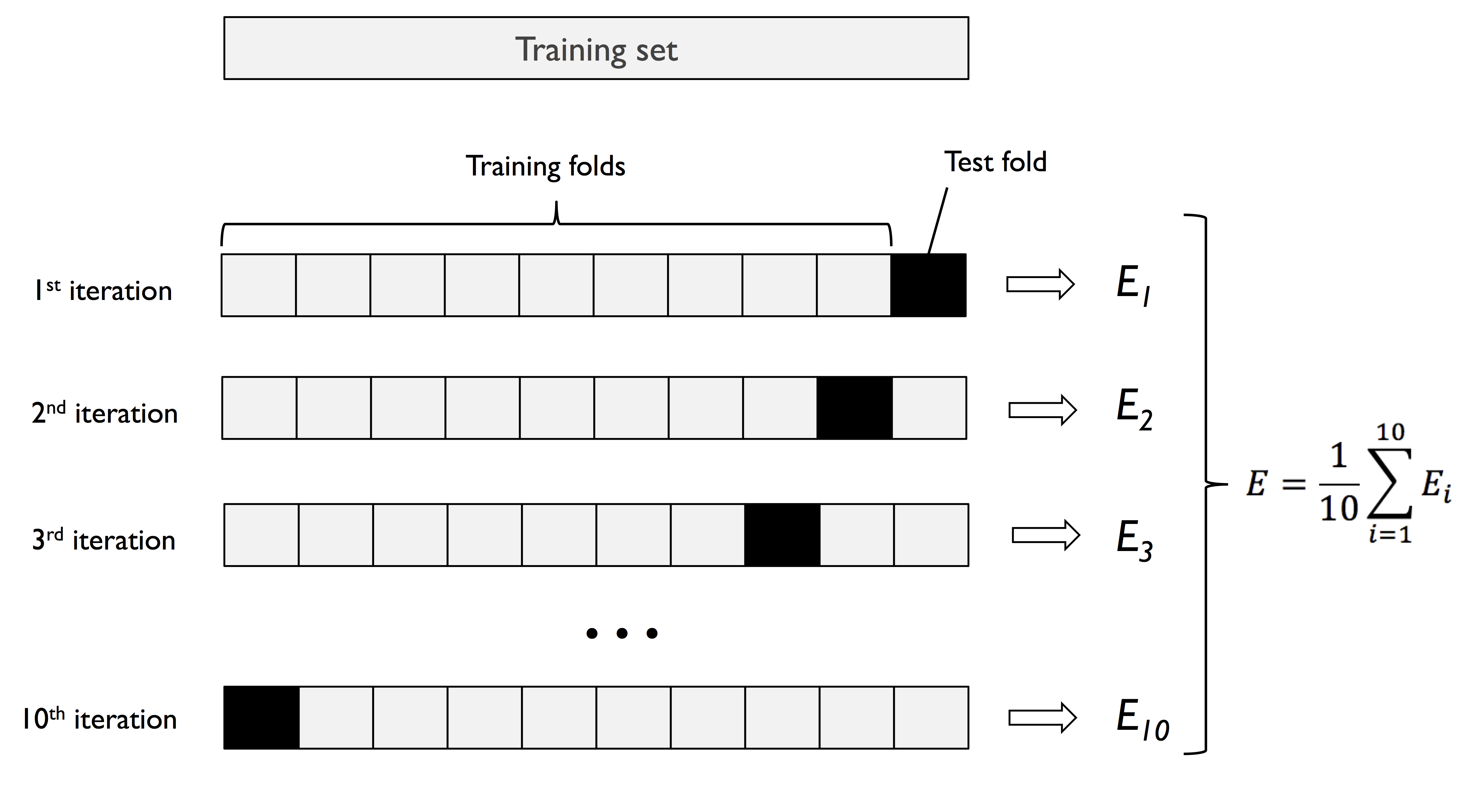
1 | from sklearn.model_selection import cross_val_score |
输入参数:
| 参数 | 意义 |
|---|---|
| estimator | 估计器 |
| X,y | 训练集 |
| cv | 交叉验证的折数(默认 5 折) |
| n_jobs | 同时使用的处理器个数(默认一般为 1,-1 为全部使用) |
返回值:
| 返回值 | 意义 |
|---|---|
| scores | 每次交叉验证的估计器的准确率 |
熟悉学习曲线的使用
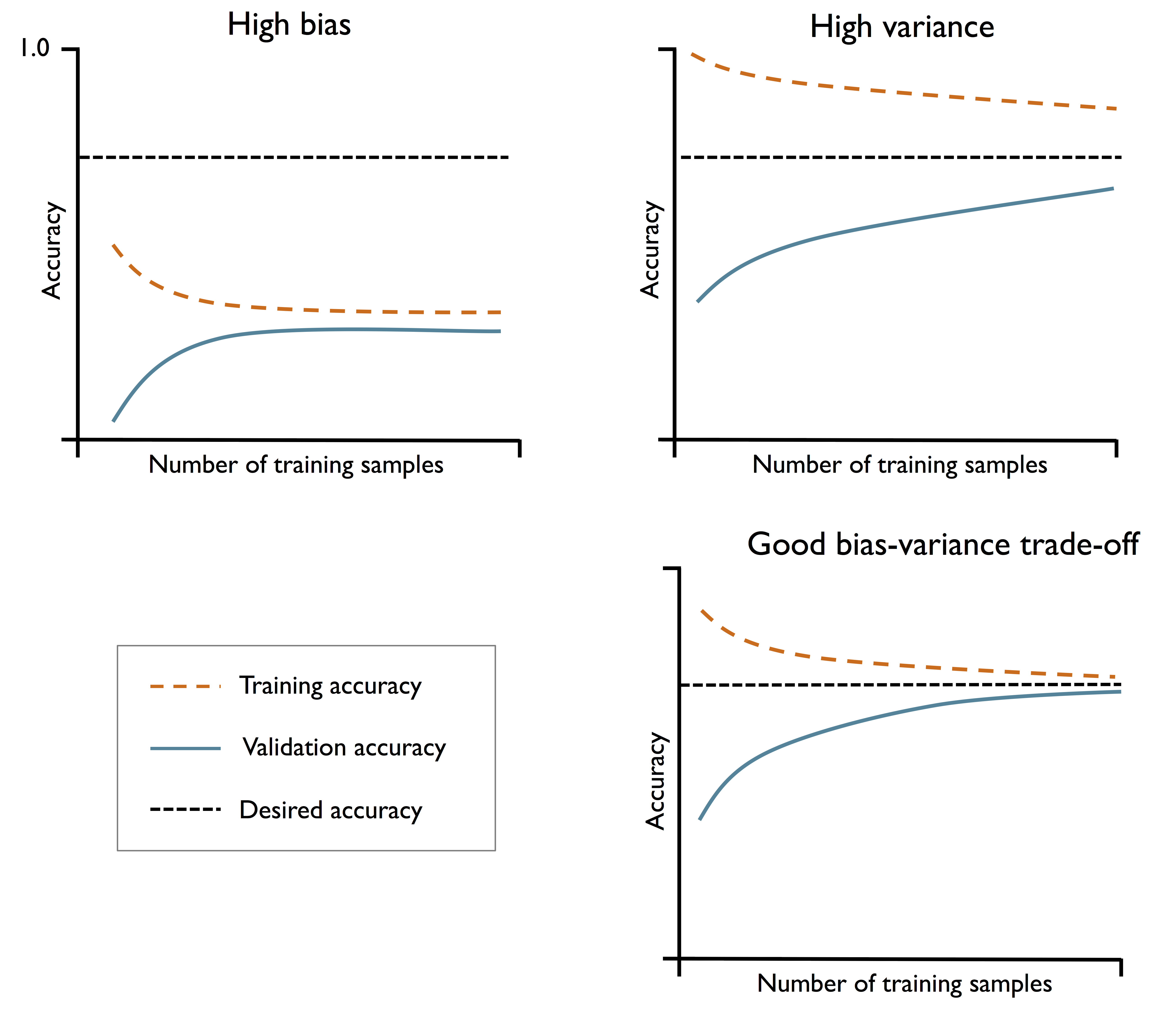
学习曲线:在训练集和验证集上,关于训练数据规模的性能曲线。用于调试算法
熟悉函数
1 | from sklearn.model_selection import learning_curve |
输入参数:
| 参数 | 意义 |
|---|---|
| estimator | 估计器 |
| X,y | 训练集 |
| train_sizes | 训练集的数量,用于生成学习曲线横坐标 |
| cv | 交叉验证的折数(默认 5 折) |
| n_jobs | 同时使用的处理器个数(默认一般为 1,-1 为全部使用) |
返回值:
| 返回值 | 意义 |
|---|---|
| train_sizes | 已用于生成学习曲线的训练示例数 |
| train_scores | 训练集得分 |
| test_scores | 测试集得分 |
修改参数实验
进行 20 次训练(train_sizes=np.linspace(0.1, 1.0, 20))
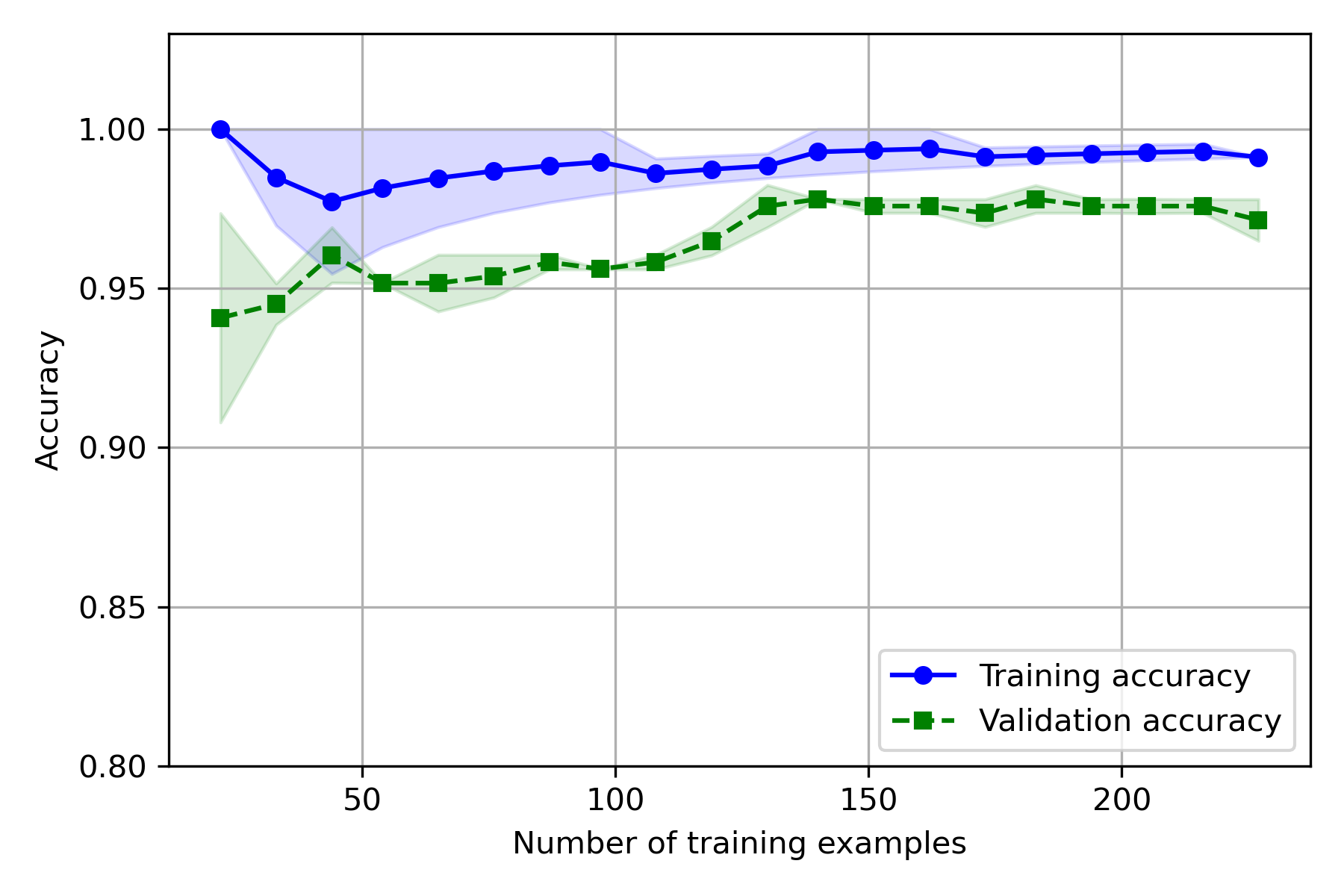
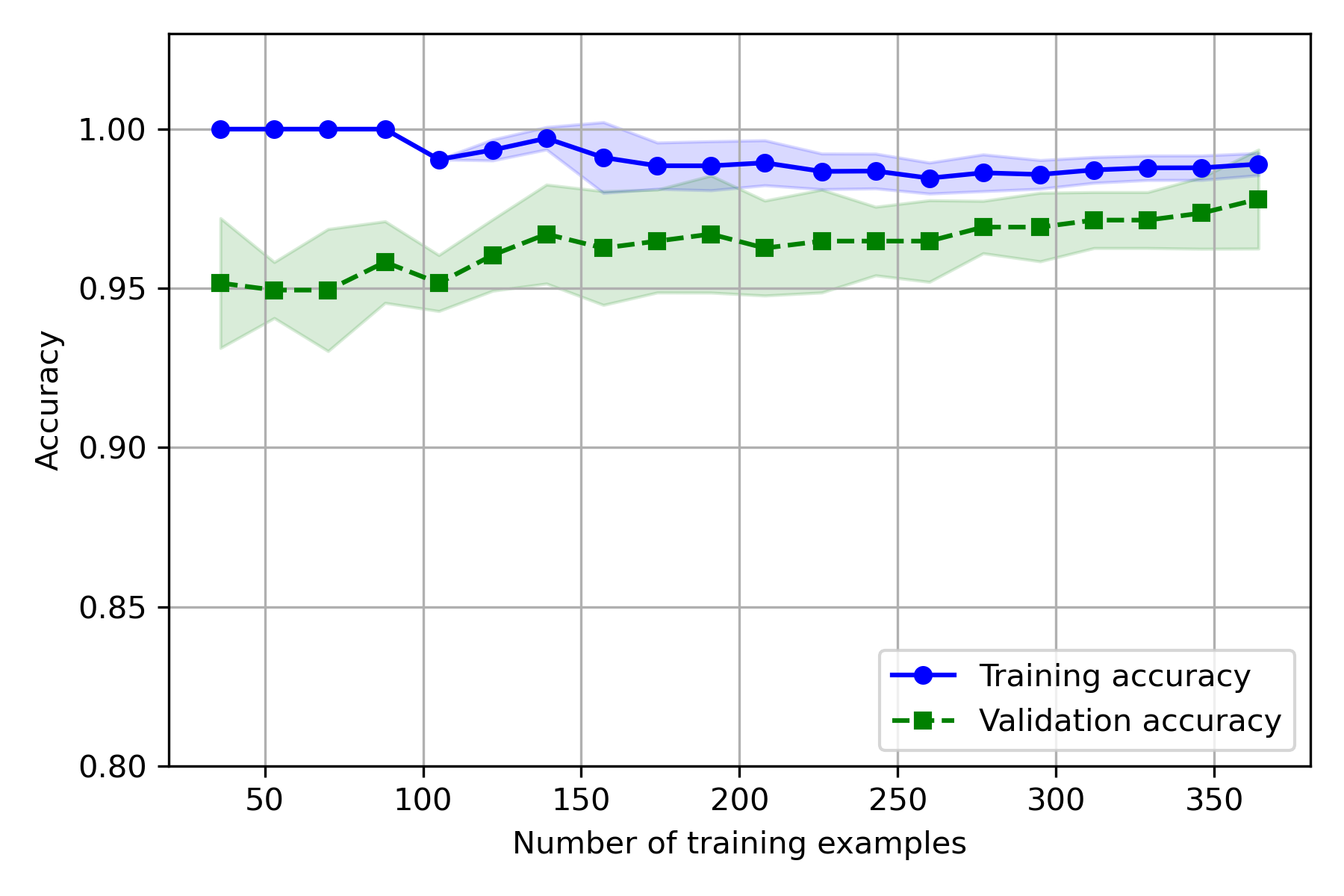
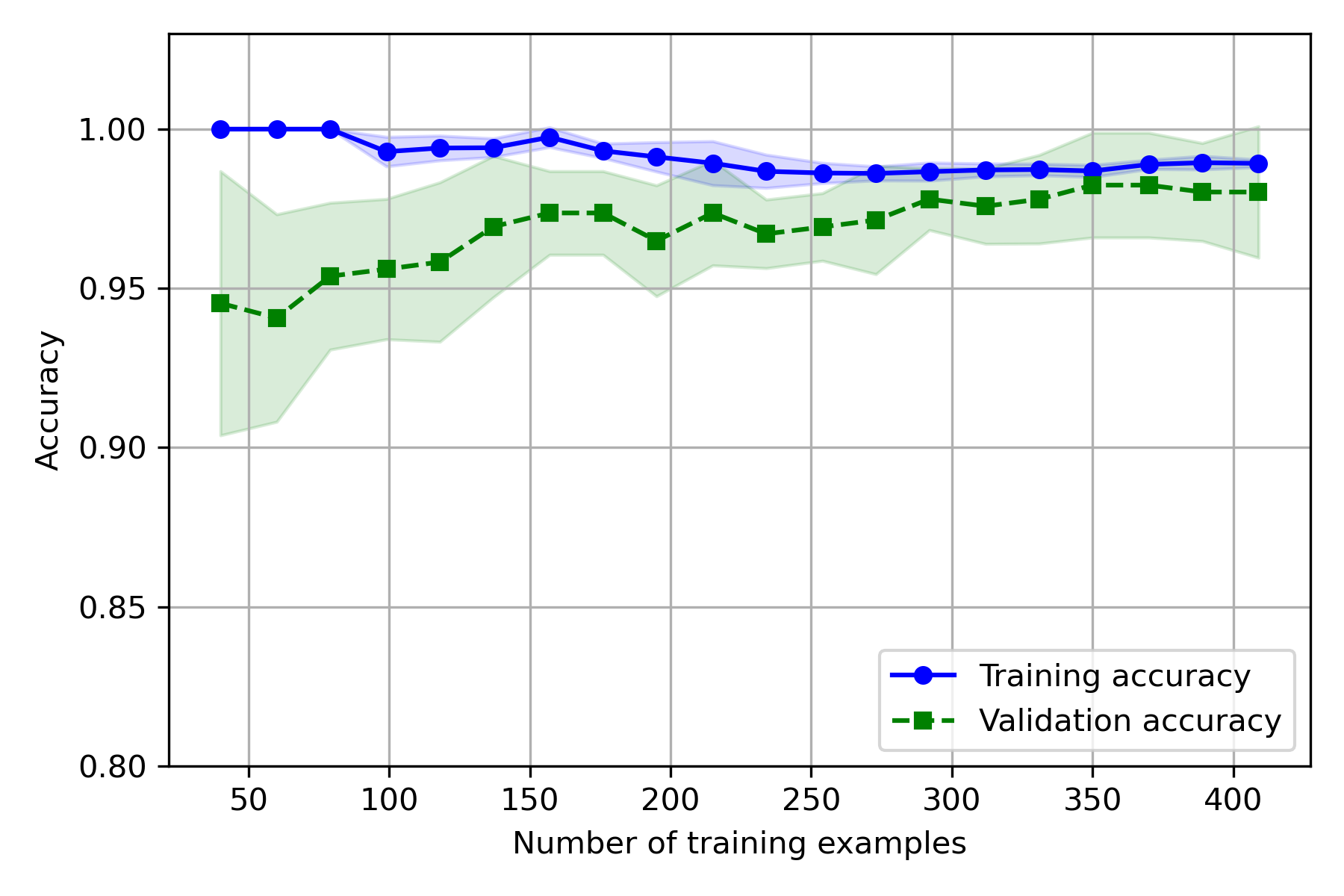
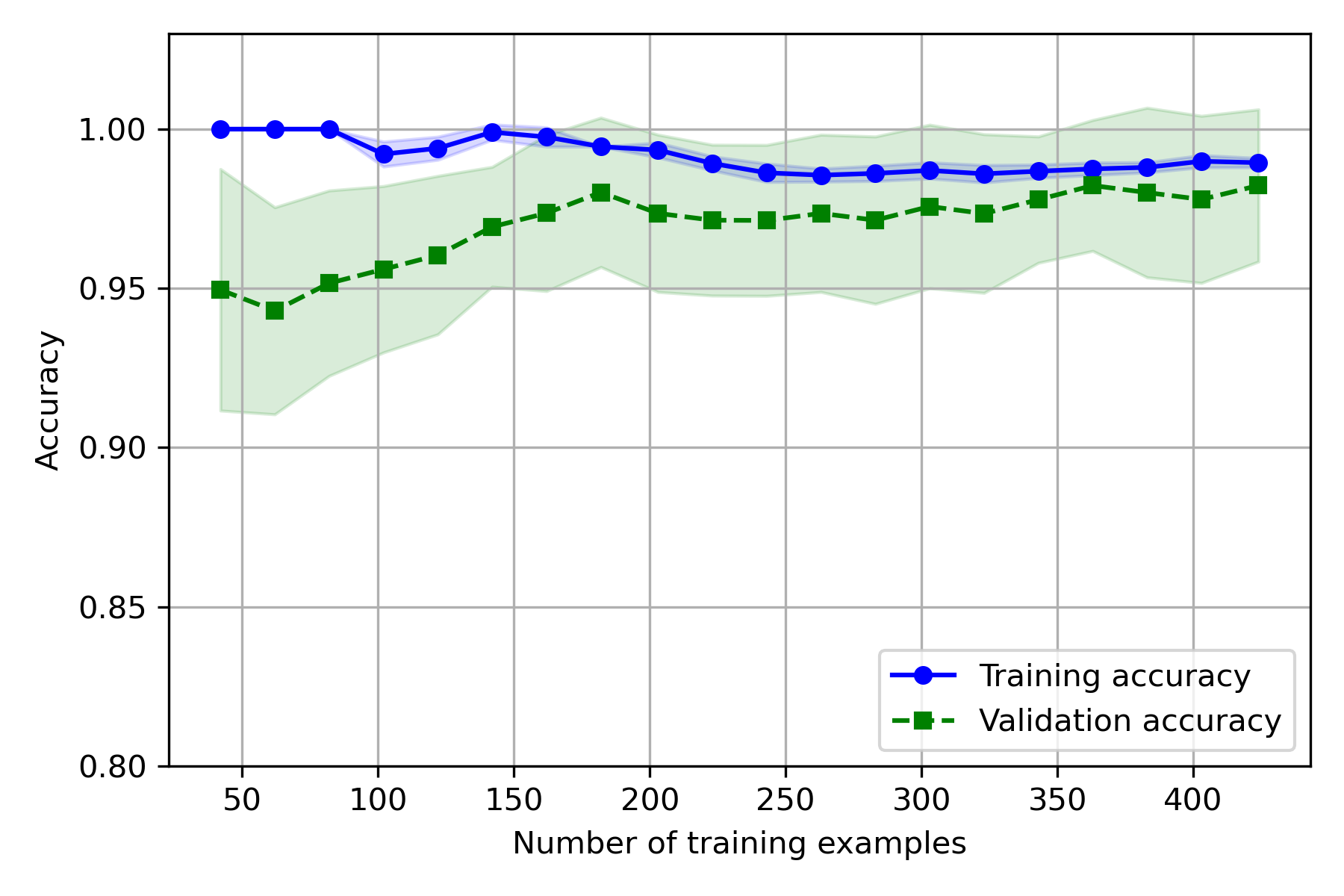
实验结果:
- 训练集上,CV 越大,偏差越大,方差越小
- 测试集上,CV 越大,偏差越小,方差越大
因为 CV 越大,用于训练的样本越多,误差增大,因此训练准确率会下降、方差变小,而测试集样本变少,测试的方差变大。
就基础代码实际使用的数据而言,模型拟合效果不错,CV 取 5~10 时,偏差和方差都较小
熟悉验证曲线的使用
验证曲线(拟合图):反映模型泛化性能(测试误差)与模型复杂度关系的曲线,用于模型选择。
要防止过拟合,就需要进行模型选择:选择复杂度适当的模型,以达到使测试误差最小的学习目的。
熟悉函数
1 | from sklearn.model_selection import validation_curve |
输入参数:
| 参数 | 意义 |
|---|---|
| estimator | 估计器 |
| X,y | 训练集 |
| param_name | 自变量名称 |
| param_range | 自变量 |
| cv | 交叉验证的折数(默认 5 折) |
返回值:
| 返回值 | 意义 |
|---|---|
| train_scores | 训练集得分 |
| test_scores | 测试集得分 |
修改参数实验
逻辑回归
修改为:param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0, 10000.0]
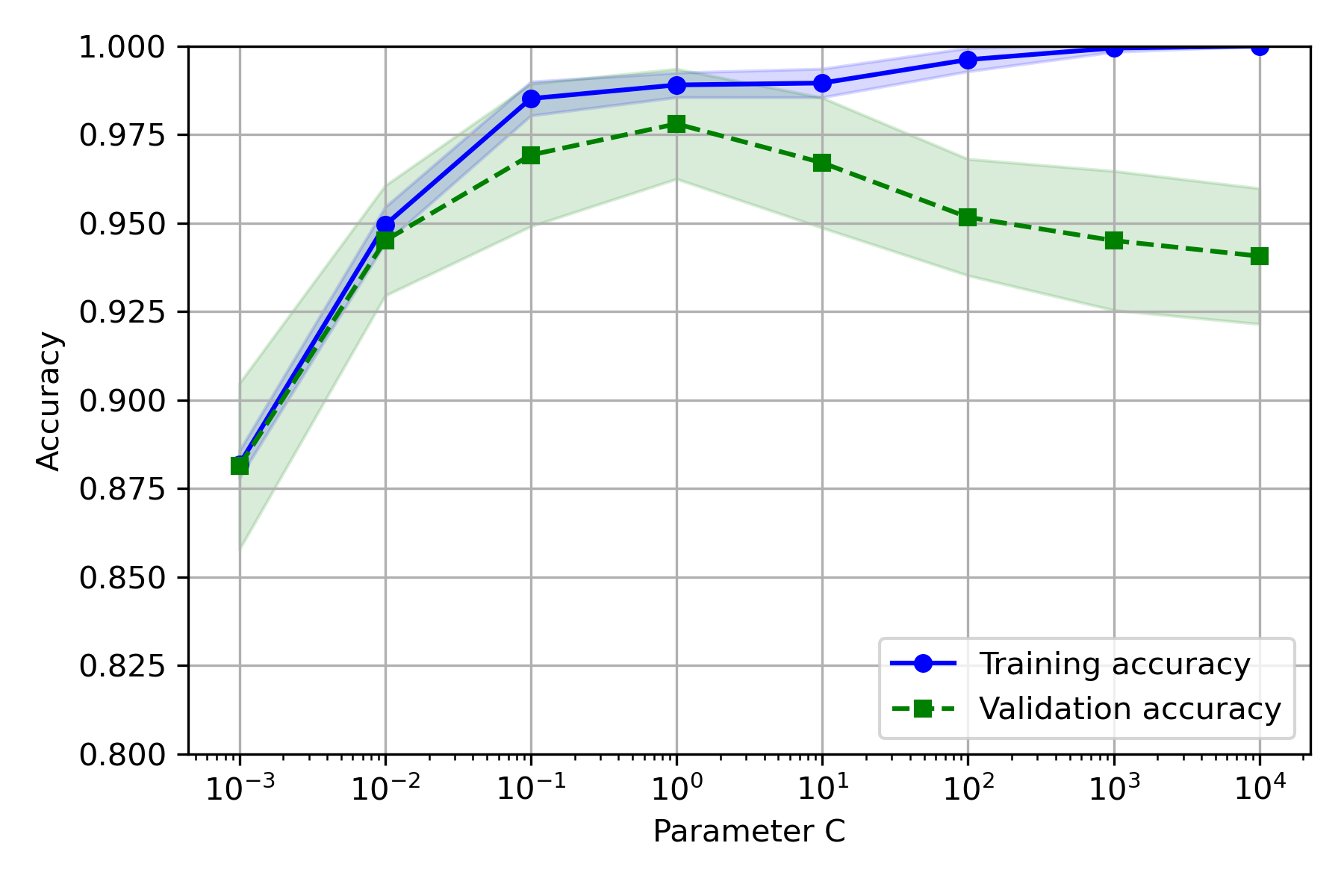
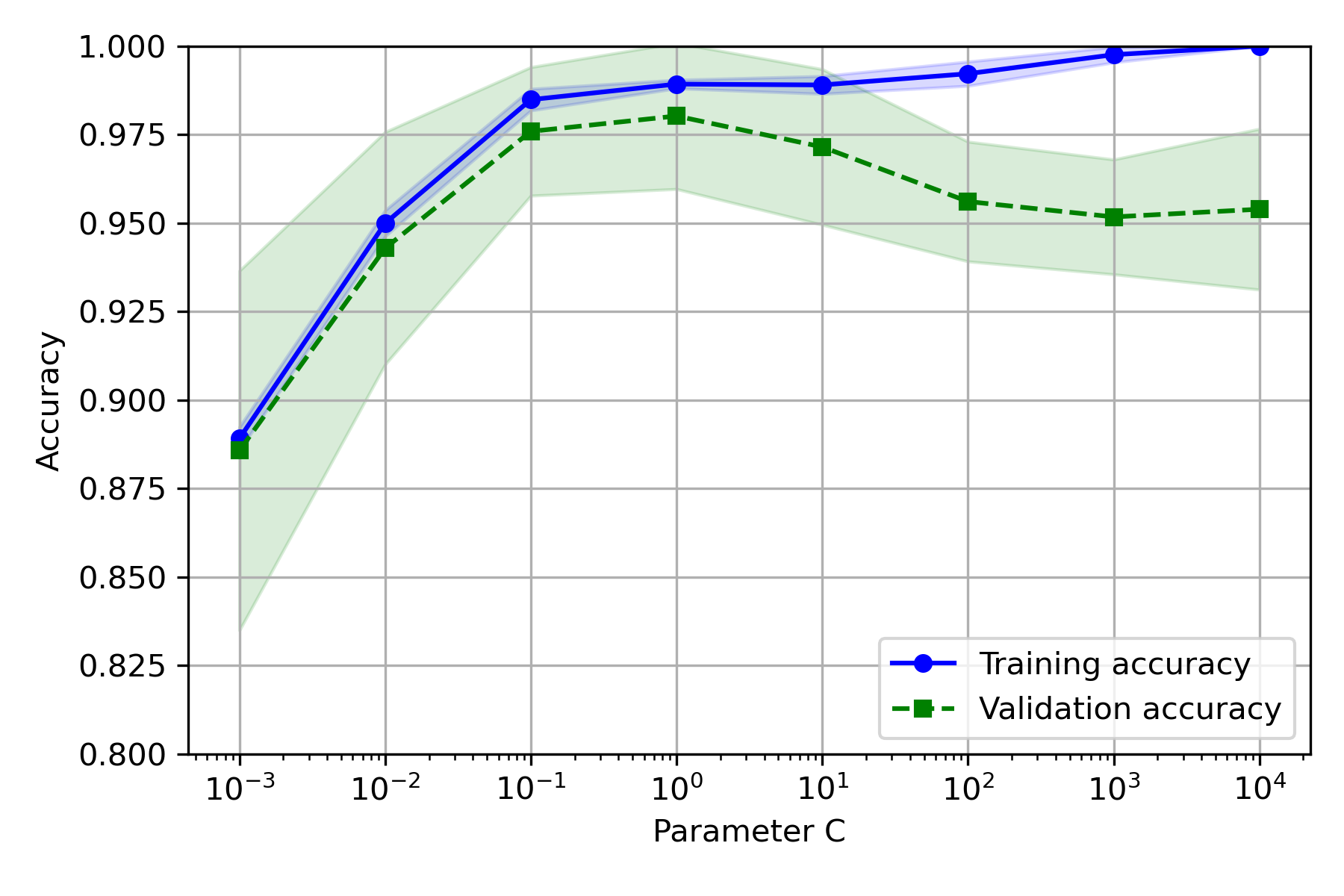
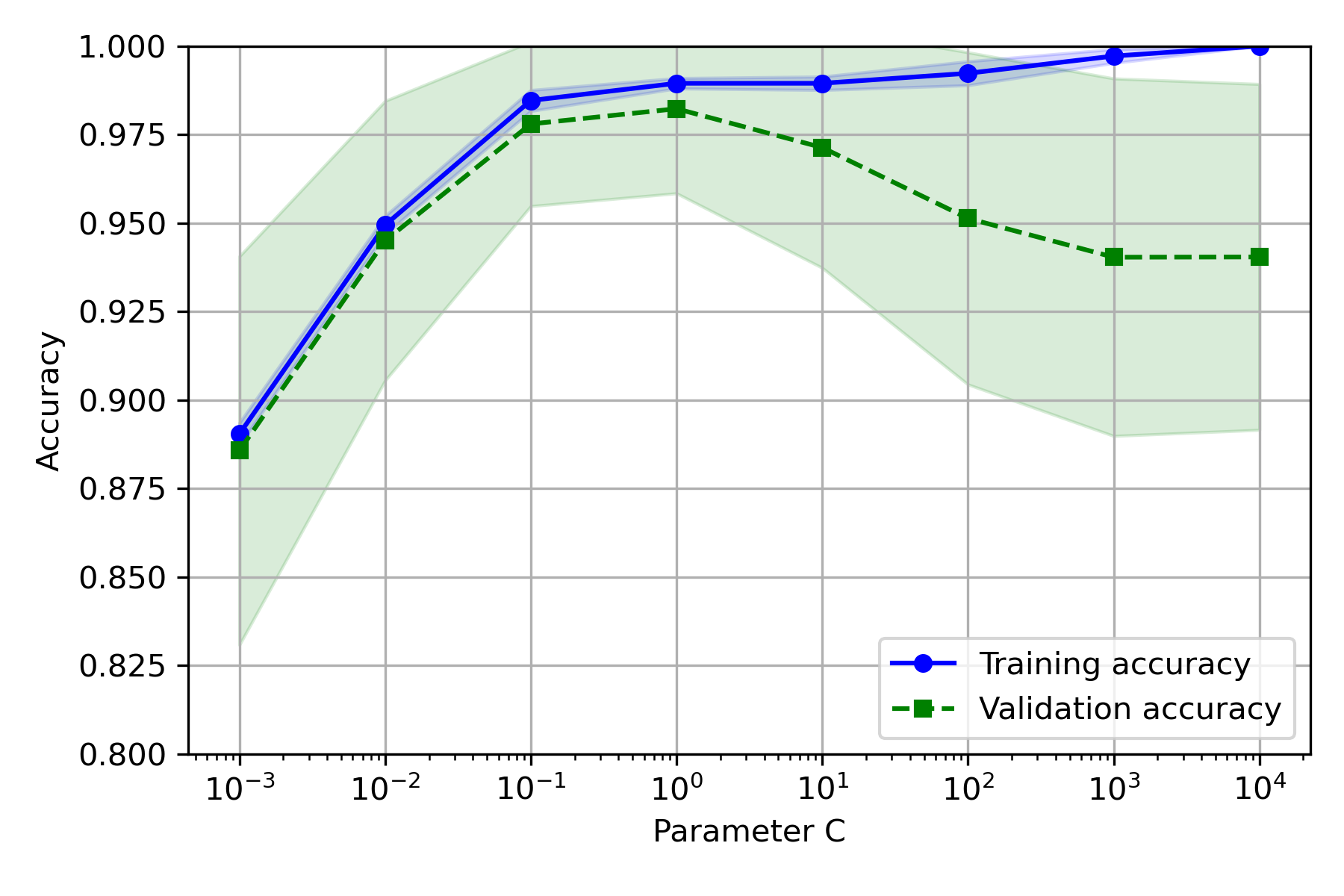
实验结果:
- CV 取 5~10 较好
- C 取 10 较好
KNN
修改代码为:
1 | from sklearn.neighbors import KNeighborsClassifier |
第 54~60 行:
1 | plt.grid() |
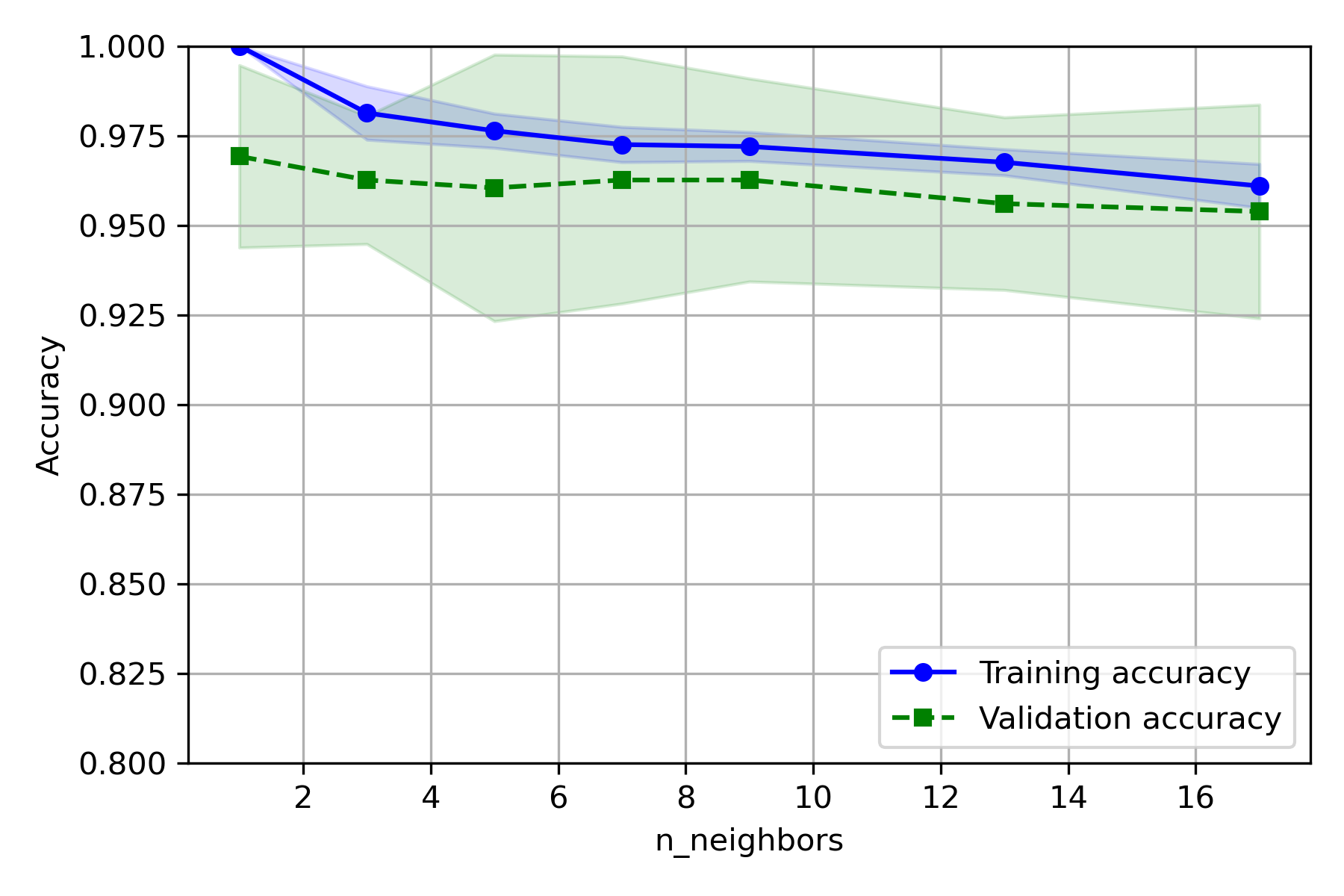
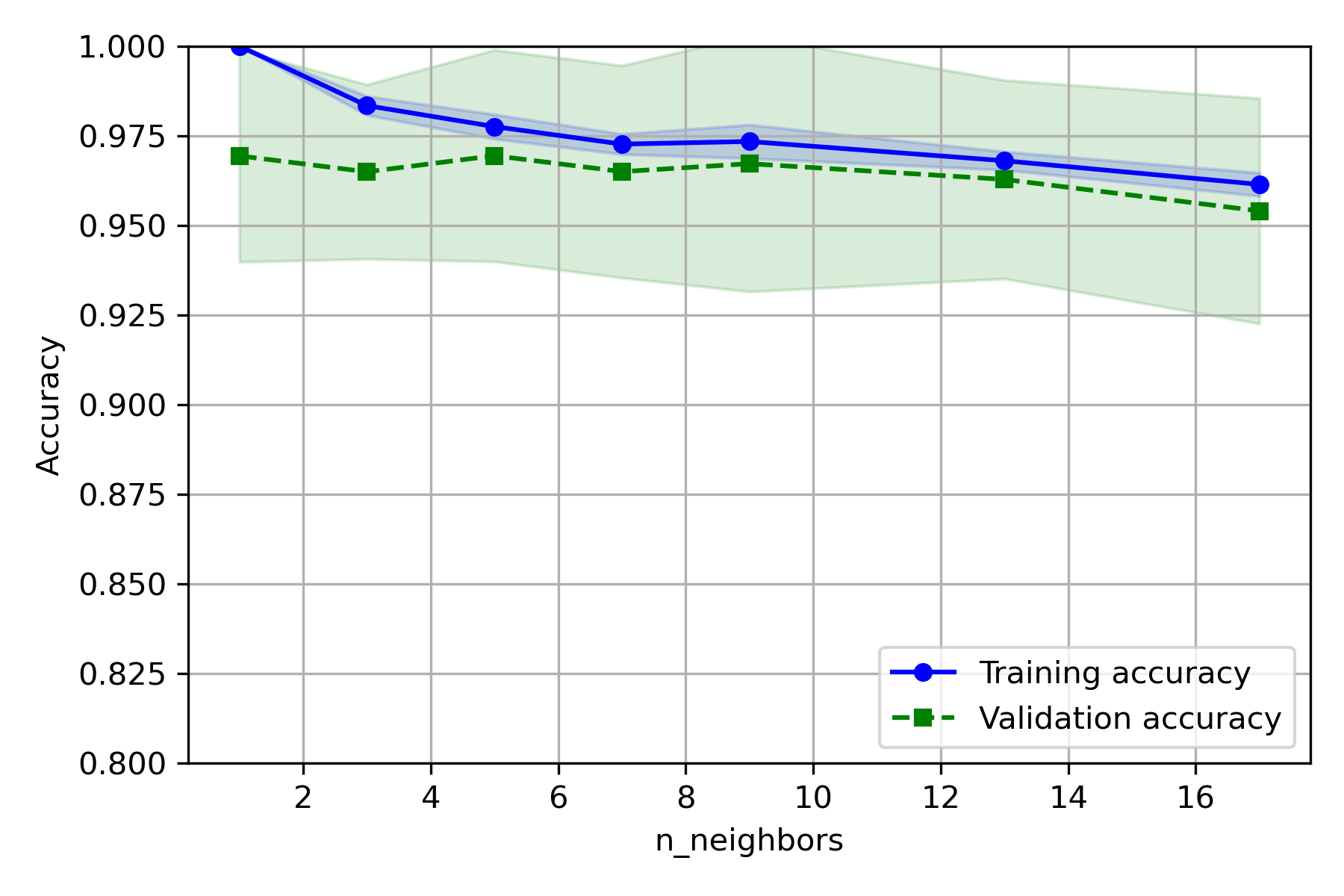
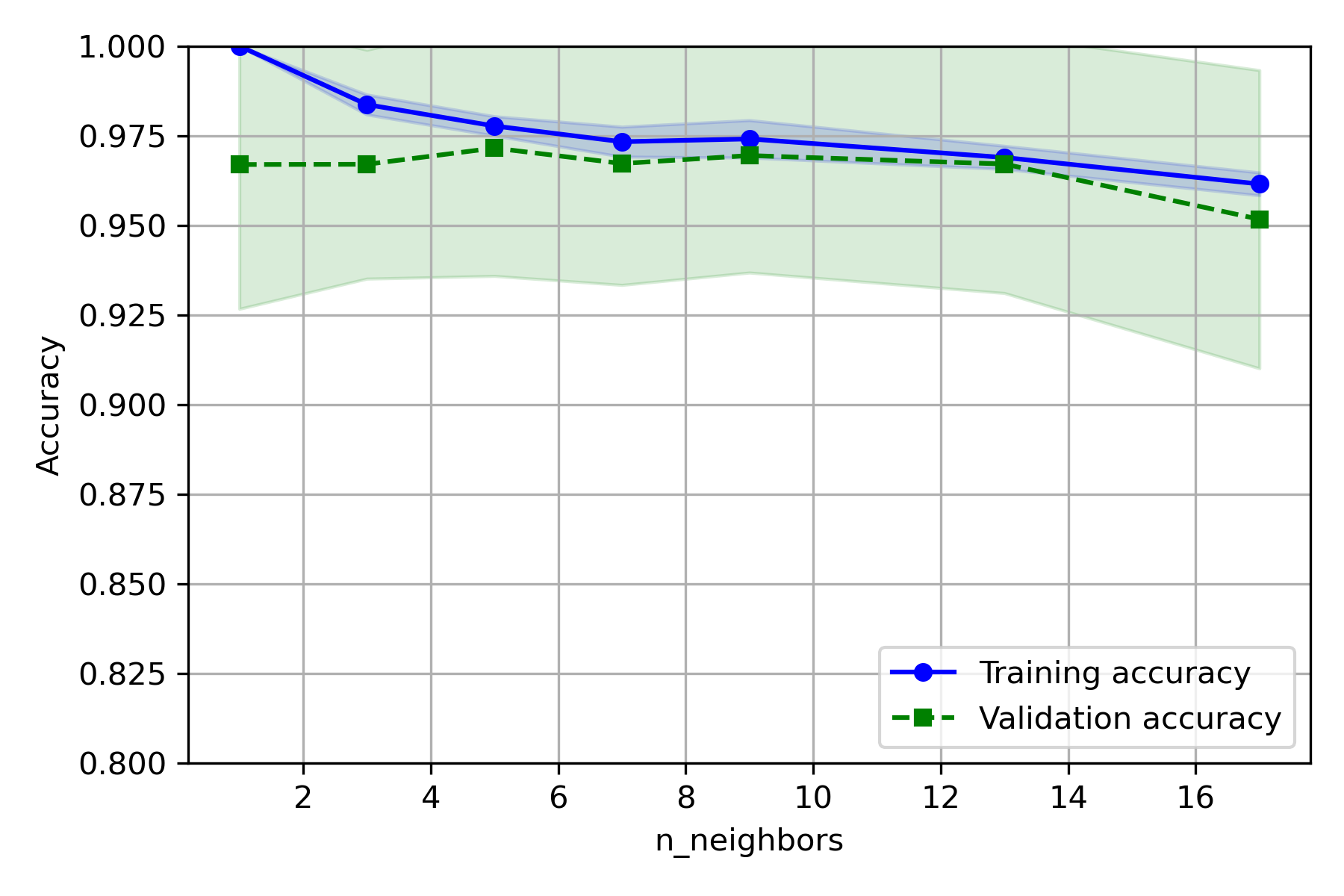
实验结果:
- CV 取 5~10 较好
- C 取 9 较好